https://twobeach.tistory.com/61
[Pytorch]pytorch를 활용한 EfficientNet 학습 코드 [1/3]
대학원 생활에 제가 직접 사용하였던 EfficientNet의 학습코드를 설명하기에 앞서 간단하게 설명을 드리면 일반적으로 이미지 분류 분야의 인공지능 모델의 정확도를 높일 때 사용되는 조건은 아
twobeach.tistory.com
학습 데이터 코드를 작성하기전 데이터 세트를 구성을 안하셨다면 위의 링크를 참고하여 주세요!!
학습 데이터 코드는 pytorch와 neptune ai라는 라이브러리를 사용하여 작성되었습니다.
neptune ai의 경우 파이썬 3.7이상의 버전에서만 동작하시기 때문에 만약 파이썬 버전이 낮으시다면 3.7이상의 파이썬 아나콘다 가상환경에서 진행을 하시거나 우분투 버전을 다른버전으로 변경하시는 것을 추천드립니다.
neptune ai는 학습을 진행할 시 각종 정보를 workspace에 맞게 그래프를 보여주거나 수치화하여 보여줍니다.
자세한 사항은 아래의 링크를 통해 확인하시길 바랍니다.
neptune.ai | ML metadata store
Manage all your model-building metadata in a single place. Track experiments, register models, integrate with any MLOps tool stack.
neptune.ai
pytorch의 버전의 경우는 파이썬 3.7이상의 버전에 맞게 설치하셨다면 크게 문제없이 돌아가실 수 있습니다.
학습코드의 경우 import할 라이브러리가 많이 있습니다. 대부분 pip를 통한 설치를 진행하시면 오류없이 진행하실수 있을겁니다.
import os ,time
import glob
import random
from PIL import Image
import torch
import torch.nn as nn
from torchvision import transforms
import torchvision.transforms.functional as TF
from torch.utils.data import Dataset, DataLoader
from torch.cuda.amp import autocast, grad_scaler
from torch.optim.lr_scheduler import _LRScheduler
import torch_optimizer as optim
import numpy as np
import pandas as pd, cv2
from tqdm import tqdm
from easydict import EasyDict
from sklearn.preprocessing import LabelEncoder #Label Encoder로 숫자로 변경함
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from ptflops import get_model_complexity_info
from collections import Counter
import argparse
import neptune.new as neptune
import timm
from efficientnet_pytorch import EfficientNet
import torchvision.models as models
#안하면 오류남
import warnings
from pandas.core.common import SettingWithCopyWarning
warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
warnings.filterwarnings(action='ignore')정상적으로 라이브러리 import가 끝나셨다면 이제 학습 코드를 진행하실 수 있습니다.
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#학습데이터 로드
train_data = pd.read_csv("/home/user/effcientNet/explosive/RP_explosive/Train_df.csv")
display(train_data)
#transform용
class GammaTranform:
def __init__(self,a,b):
self.a = a
self.b = b
def __call__(self, I):
gamma = random.uniform(self.a, self.b)
return TF.adjust_gamma(I,gam)
#transform
def augmentation(img_size, ver):
if ver==1:
transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==2:
transform = transforms.Compose([
transforms.RandomRotation(degrees=20),
transforms.RandomAffine(degrees=(10,30)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==3:
transform = transforms.Compose([
transforms.RandomRotation(degrees=180),
transforms.RandomAffine(degrees=(10,30)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==4:
transform = transforms.Compose([
transforms.RandomRotation(degrees=20),
transforms.RandomAffine(degrees=(10,30)),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==5:
transform = transforms.Compose([
transforms.RandomRotation(degrees=180),
transforms.RandomAffine(degrees=(10,30)),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==6:
transform = transforms.Compose([
transforms.RandomRotation(degrees=180),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomAffine(30),
transforms.ColorJitter(),
transforms.RandomInvert(),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==7:
transform = transforms.Compose([
transforms.RandomRotation(degrees=180),
transforms.RandomAffine(degrees=45),
transforms.Resize((img_size, img_size)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==8:
transform = transforms.Compose([
transforms.RandomRotation(degrees=10),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomAffine(30),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==9:
transform = transforms.Compose([
transforms.RandomRotation(degrees=(0,180)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomAffine(30),
GammaTransform(0.6,1.0),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==10:
transform = transforms.Compose([
transforms.RandomRotation(degrees=(180)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomAffine(30),
transforms.ColorJitter(),
transforms.RandomInvert(),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
elif ver==11:
transform = transforms.Compose([
transforms.RandomRotation(degrees=20),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Resize((img_size, img_size)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
return transform위의 ver 함수 같은경우 이미지의 각도를 변경하면서 진행하는 겁니다. 적절한 ver버전을 맞춰서 학습을 진행하시면 됩니다. Normalize 같은 경우는 논문에서 제시하는 공식코드에서 제공하는 값이므로 수정하시지 말기를 권고드립니다.
class Train_Dataset(Dataset):
def __init__(self, df, transform=None, is_training=False):
self.file_name = df['file_name'].values
self.label = df['label'].values
self.transform = transform
self.is_training = is_training
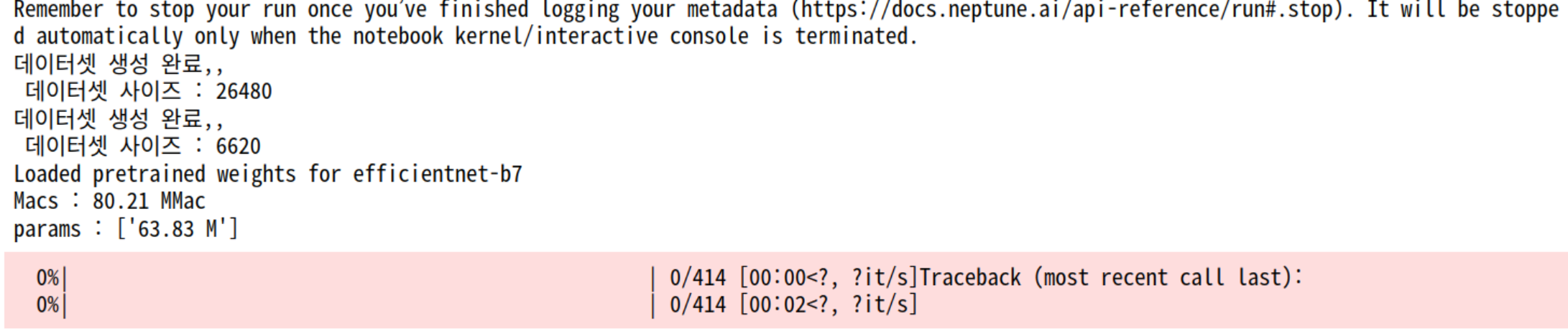
print(f"데이터셋 생성 완료,,\n 데이터셋 사이즈 : {len(self.file_name)}")
def __getitem__(self, index):
img_path = self.file_name[index]
image = cv2.imread(img_path).astype(np.float32) #numpy형식으로 불러옴
label = self.label[index]
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)/ 255.0 #데이터 증강을 위해 바꿈
image_transform = self.transform
#image transform 시행
image = image.transpose(2,0,1) #HWC ->> CHW
image = image_transform(torch.from_numpy(image))
return image, label
def __len__(self):
return len(self.file_name)
class Test_Dataset(Dataset):
def __init__(self, df, transform=None):
self.file_name = df['file_name'].values
self.transform = transform
print(f"테스트 데이터셋 생성 완료,,\n 데이터셋 사이즈 : {len(self.file_name)}")
def __getitem__(self, index):
image = np.array(Image.open(self.file_name[index]).convert('RGB'))
if self.transform is not None:
image = self.transform(Image.fromarray(image))
return image
def __len__(self):
return len(self.file_name)
def get_loader(df, phase: str, batch_size, shuffle, num_workers, transform, is_training=False):
if phase == 'test':
dataset = Test_Dataset(df, transform)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers, pin_memory=True)
else:
dataset = Train_Dataset(df, transform, is_training=is_training)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers, pin_memory=True, drop_last=False)
return data_loader
위의 함수들은 학습을 위한 함수들이며 데이터 로드 및 검증 데이터 세트와 학습 데이터 세트를 구성해주는 코드입니다.
밑의 코드의 경우 학습에 진행할 때 사용되는 parameter를 조절하는 부분입니다. data_path와 file_name과 batch_size는 본인에 맞게 수정하시는 것을 추천드립니다. img_size와 batch_size는 학습할 때 변경하도록 합시다. 논문에서 제시하는 최적의 default 값은 224x224입니다.
def getConfig():
parser = argparse.ArgumentParser()
parser.add_argument('--data_path', type=str, default='/home/user/effcientNet/explosive/RP_explosive')
parser.add_argument('--file_name', type=str, default='train.csv')
parser.add_argument('--fold', type=int, default=0, help='Validation Fold')
parser.add_argument('--Kfold', type=int, default=5, help='Number of Split Folds')
parser.add_argument('--tag', default='PetFriends', type=str, help='tag')
# Model parameter settings
parser.add_argument('--model_type', type=str, default='', help='CNN or Transformer')
parser.add_argument('--encoder_name', type=str, default='regnety_040') #regnety 모델사용
parser.add_argument('--drop_path_rate', type=float, default=0.2)
parser.add_argument('--num_classes', type=int, default=17)
# Training parameter settings
## Base Parameter
parser.add_argument('--epochs', type=int, default=50)
parser.add_argument('--img_size', type=int, default=256)
parser.add_argument('--batch_size', type=int, default=128)
parser.add_argument('--initial_lr', type=float, default=1e-5)
parser.add_argument('--weight_decay', type=float, default=1e-4)
## Augmentation
parser.add_argument('--aug_ver', type=int, default=1)
### Cosine Annealing
parser.add_argument('--warm_epoch', type=int, default=45) # WarmUp Scheduler
parser.add_argument('--max_lr', type=float, default=1e-3)
parser.add_argument('--patience', type=int, default=300, help='Early Stopping')
parser.add_argument('--use_aug', type=bool, default=False, help='augmentation for pill and zipper')
# Hardware settings
parser.add_argument('--logging', type=bool, default=True)
parser.add_argument('--num_workers', type=int, default=4)
parser.add_argument('--seed', type=int, default=42)
args,_ = parser.parse_known_args()
return args
class Net(nn.Module):
def __init__(self, args):
super().__init__()
#timm
#self.encoder = timm.create_model(args.encoder_name, pretrained=True, drop_path_rate = args.drop_path_rate, num_classes = args.num_classes)
#EfficientNet 모듈 timm에도 EfficientNet이 있지만 사전학습이 더 잘되어있음.
self.encoder = EfficientNet.from_pretrained(args.encoder_name,num_classes = args.num_classes )
def forward(self, x):
x = self.encoder(x)
return x밑의 코드는 학습에 대한 여러 세팅 값들이며 기본적으로 acc, loss, f1-score로 모델을 학습 모델을 검증하게 됩니다. 옵티마이저함수와 loss 함수는 본인이 원하는 것을 수정해서 사용하셔도 됩니다.
class Set_lr(_LRScheduler):
def __init__(self, optimizer, total_iters, last_epoch=-1):
self.total_iters = total_iters
super(Set_lr,self).__init__(optimizer, last_epoch=last_epoch)
def get_lr(self):
return [base_lr * self.last_epoch / (self.total_iters + 1e-7) for base_lr in self.base_lrs]
class Loss_setting(object):
def __init__(self, num=40):
self.num = num
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
self.losses = []
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
self.losses.append(val)
class Trainer():
def __init__(self, args, try_count):
super(Trainer, self).__init__()
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
save_path = os.path.join('result/', str(try_count).zfill(3))
os.makedirs(save_path, exist_ok=True)
#neptune ai
#netune ai :학습 그래프를 그려주는 모듈
run = neptune.init(
project="여기에 neptune 프로젝트 workspace를 넣으시면 됩니다.",#input yout project
api_token="여기에 neptune 가입 후 나오는 api 토큰을 넣으시면 됩니다.", #input your token
) # your credentials
run["parameters"] = args
# Train, Valid Dataset Load
train_data = pd.read_csv(os.path.join(args.data_path, args.file_name))
#Fold Setting
KFold = kf = StratifiedKFold(n_splits=args.Kfold)
for fold_num,(_,val_idx) in enumerate(KFold.split(train_data, y = train_data['label'])):
train_data.loc[val_idx,'fold'] = fold_num
val_data = train_data[train_data['fold'] == args.fold].reset_index(drop=True)
train_data = train_data[train_data['fold'] != args.fold].reset_index(drop=True)
#Data Augmentation
self.train_transform = augmentation(img_size=args.img_size, ver=args.aug_ver)
self.test_transform = augmentation(img_size=args.img_size, ver=1)
#Load Train Data
self.train_loader = get_loader(train_data, phase='train', batch_size=args.batch_size, shuffle=True,
num_workers=args.num_workers, transform=self.train_transform, is_training=args.use_aug)
self.val_loader = get_loader(val_data, phase='train', batch_size=args.batch_size, shuffle=False,
num_workers=args.num_workers, transform=self.test_transform, is_training=False)
#Model Load
self.model = Net(args).to(self.device)
amcs, params = get_model_complexity_info(self.model, (3,args.img_size, args.img_size), as_strings=True,
print_per_layer_stat=False, verbose=False)
print(f'Macs : {amcs}')
print(f'params : {[params]}')
#Loss
self.criterion = nn.CrossEntropyLoss() #loss 다른거 쓰려면 다른거 넣으시면됩니다.
#Optimizer
self.optimizer = optim.Lamb(self.model.parameters(), lr=args.initial_lr, weight_decay=args.weight_decay)
iter_per_epoch = len(self.train_loader)
#Scheduler
#OneCyecleLR 사용했으나 다른걸 사용해도 됩니다.
self.warmup_scheduler = Set_lr(self.optimizer, iter_per_epoch * args.warm_epoch)
self.scheduler = torch.optim.lr_scheduler.OneCycleLR(self.optimizer, max_lr=args.max_lr, steps_per_epoch=iter_per_epoch, epochs=args.epochs)
load_epoch=0
#Train, Val
best_loss = np.inf
best_acc = 0
best_f1 = 0
best_epoch = 0
early_stopping = 0
start = time.time()
for epoch in range(load_epoch+1, args.epochs+1):
self.epoch = epoch
if epoch > args.warm_epoch:
self.scheduler.step()
train_loss, train_acc, train_f1 = self.training(args)
state_dict = self.model.state_dict() #Save
val_loss, val_acc, val_f1 = self.validate(phase='val')
#neptune 에 기록
if args.logging == True:
run['Train loss'].log(train_loss)
run['Train acc'].log(train_acc)
run['Train f1'].log(train_f1)
run['val loss'].log(val_loss)
run['val acc'].log(val_acc)
run['val f1'].log(val_f1)
#Save Model
if val_loss < best_loss:
early_stopping = 0
best_epoch = epoch
best_loss = val_loss
best_acc = val_acc
best_f1 = val_f1
torch.save({'epoch':epoch,
'state_dict':state_dict,
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict(),}, os.path.join(save_path,'efficientnet-b3_best_model.pth'))
print(f"SAVE: {best_epoch}epoch")
else:
early_stopping += 1
if early_stopping == args.patience: #계속 발전이 없으면 중지시킴
break
if epoch == args.epochs:
torch.save({'epoch':epoch,
'state_dict':state_dict,
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict(),
}, os.path.join(save_path,'efficientnet_b3_batch64.pth'))
print('---SAVE: last epoch--------')
#epoch끝
print(f"Best Val Epoch:{best_epoch}, Val Loss : {best_loss}, Val Acc:{best_acc}, Best Val F1:{best_f1}")
end = time.time()
print(f"Total Process time:{(end - start) / 60:.3f}Minute")
run["Best result"] = {
"Best_epoch" : best_epoch,
"Best_loss" : best_loss,
"best_acc" : best_acc,
"best_f1" : best_f1,
}
run.stop()# neptune stop
def training(self, args):
self.model.train()
train_loss = Loss_setting()
train_acc = 0
preds_list = []
labels_list = []
scaler = grad_scaler.GradScaler()
for i, (images, labels) in enumerate(tqdm(self.train_loader)):
images = torch.tensor(images, device=self.device, dtype=torch.float32)
labels = torch.tensor(labels, device=self.device, dtype=torch.long)
if self.epoch <= args.warm_epoch:
self.warmup_scheduler.step()
self.model.zero_grad(set_to_none=True)
with autocast():
preds = self.model(images)
loss = self.criterion(preds, labels)
scaler.scale(loss).backward()
scaler.step(self.optimizer)
scaler.update()
# Metric
train_acc += (preds.argmax(dim=1) == labels).sum().item()
preds_list.extend(preds.argmax(dim=1).cpu().detach().numpy())
labels_list.extend(labels.cpu().detach().numpy())
train_loss.update(loss.item(), n=images.size(0))
train_acc /= len(self.train_loader.dataset)
train_f1 = f1_score(np.array(labels_list), np.array(preds_list), average='macro')
print(f'Epoch:[{self.epoch}/{args.epochs}]')
print(f'Train Loss:{train_loss.avg} | Acc:{train_acc} | F1:{train_f1}')
return train_loss.avg, train_acc, train_f1
def validate(self, phase='val'):
self.model.eval()
with torch.no_grad():
val_loss = Loss_setting()
val_acc = 0
preds_list = []
labels_list = []
for images, labels in tqdm(self.val_loader):
images = torch.tensor(images, device=self.device, dtype=torch.float32)
labels = torch.tensor(labels, device=self.device, dtype=torch.long)
preds = self.model(images)
loss = self.criterion(preds, labels)
val_acc += (preds.argmax(dim=1) == labels).sum().item()
preds_list.extend(preds.argmax(dim=1).cpu().detach().numpy())
labels_list.extend(labels.cpu().detach().numpy())
val_loss.update(loss.item(), n=images.size(0))
val_acc /= len(self.val_loader.dataset)
val_f1 = f1_score(np.array(labels_list), np.array(preds_list), average='macro')
print(f'{phase} Loss:{val_loss.avg} | Acc:{val_acc} | F1:{val_f1}')
return val_loss.avg, val_acc, val_f1
args = getConfig()이제 학습을 진행해봅시다.
# Random Seed
seed = args.seed
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = True
args.batch_size = 64 # batch size는 본인의 gpu역량으로 수정가능
args.encoder_name = "efficientnet-b7"#모델은 b0에서 b7까지 있음
args.img_size= 224 #224말고 다른 사이즈로 진행해도 무방 default값이 224인 것뿐
args.aug_ver=11
args.epochs=300 #arg부분에 patience 부분에 early stopping기능이 있음
args.warm_epoch=5
args.file_name="Train_df.csv"
args.initial_lr = 1e-6
Trainer(args, 1)arg 부분에 patience의 값을 조절하여 early stopping을 할 수 있습니다. early stopping의 경우 훈련 할 때 acc, loss를 참고하여 점수를 부여하는데 그 값이 설정한 횟수만큼 나아지지 않거나 하락하는 경우 학습이 중단되게 하는 기능입니다. 유용하니 학습시 사용하시길 바랍니다.
EfficientNet 같은 경우 학습 횟수(epoch)가 많이 할 수록 결과가 안좋아지는 경우가 많으니 훈련시 유의하시길 바랍니다!!
'인공지능 > 실습' 카테고리의 다른 글
| [pytorch]pytorch를 이용한 EfficientNet 이미지 분류 (0) | 2022.11.21 |
|---|---|
| [Pytorch]pytorch를 활용한 EfficientNet 학습 코드 [3/3] (0) | 2022.11.18 |
| [Pytorch]pytorch를 활용한 EfficientNet 학습 코드 [1/3] (0) | 2022.11.18 |
| [GAN] GAN으로 증강 된 시계열 데이터 평가 (0) | 2021.06.24 |
| [GAN] GAN을 이용한 시계열 데이터 생성 (0) | 2021.03.30 |