728x90

위의 csv파일을 이용하여 작성되었습니다.
1. 라이브러리 입력
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
import tensorflow as tf
2. csv파일 입력
df = pd.read_excel("TNT_TSC.csv")
print(df)
df.head()

3. 데이터 가공
a = TNT
b = RDX
c,d = PETN
df.POS.value_counts()df = df[['POS', 'time(sec)','a', 'b', 'c', 'd']]
print(df)
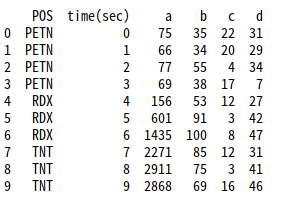
4. train, test set으로 나누기
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.2)
train.shape[0]test.shape[0]train.to_csv("tsc_train.csv", index = None)
test.to_csv("tsc_test.csv", index = None)
5. 최적의 k를 찾기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
#나눗셈의 몫을 최댓값으로 지정
max_k_range = train.shape[0] // 2
#3개의 k값이 산출
k_list = []
for i in range(1, max_k_range, 1):
k_list.append(i)
print(len(k_list))
cross_validation_scores = []
x_train = train[['a', 'b', 'c', 'd']]
y_train = train[['POS']]
for k in k_list:
knn = KNeighborsClassifier(n_neighbors=k)
acc = cross_val_score(knn, x_train, y_train.values.ravel(),
cv=2, scoring='accuracy')
cross_validation_scores.append(acc.mean())
cross_validation_scores

cvs = cross_validation_scores
k = k_list[cvs.index(max(cross_validation_scores))]
print("The best num k = " + str(k))

5. 최종결과
첫번째 k의 값이 가장 잘나왔고 이것을 이용해서 훈련을 진행
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
knn = KNeighborsClassifier(n_neighbors= k)
x_train = train[['a', 'b', 'c', 'd']]
y_train = train[['POS']]
knn.fit(x_train, y_train.values.ravel())
x_test = test[['a', 'b', 'c', 'd']]
y_test = test['POS']
pred = knn.predict(x_test)
comparison = pd.DataFrame({'예측 값 ':pred, '원래 적어둔 값':y_test.values.ravel()})
print(comparison)
print("accuracy : " + str(accuracy_score(y_test.values.ravel(), pred)))
728x90
'인공지능 > 실습' 카테고리의 다른 글
| [GAN] GAN을 이용한 시계열 데이터 생성 (0) | 2021.03.30 |
|---|---|
| [pytorch]pytorch를 이용한 stylegan2 ada 실습 (0) | 2021.02.05 |
| [SimpleRNN, LSTM, GRU]를 이용한 영화감상평 실습 (0) | 2021.01.19 |
| [LSTM]을 이용해서 삼성전자 주식 예측해보기 (0) | 2020.12.01 |
| [tensorflow GAN]tensorflow GAN(심층 합성곱 생성적 적대 신경망) 기본예제 (0) | 2020.11.26 |